SGPLOTプロシジャ ①経時測定データ編
SGPLOTプロシジャは非常に柔軟にグラフを作成できる大変便利なプロシジャです。作成できるグラフは多岐に渡るので、何回かに分けてまとめていきたいと思います。第1回目は経時測定データです。
まずデータセットの作成です。
data d1;
call streaminit(915); /*乱数再現可能な乱数シードの設定*/
do ID=1 to 100;
group=rand("table", 1/2, 1/2); /*2群の乱数生成*/
do visit=1 to 5;
bp=rand("normal", 150-(visit)*group , 10 ); /*各時点での正規乱数による値の生成*/
output;
end;
end;
run;
proc format; /*出力時のラベルを指定*/
value groupf 1="対照群" 2="介入群";
run;
proc print data=d1;
format group groupf. ; /変数groupのラベルをgroupfに*/
run;
| Obs | ID | group | visit | bp |
|---|---|---|---|---|
| 1 | 1 | 対照群 | 1 | 147.659 |
| 2 | 1 | 対照群 | 2 | 141.000 |
| 3 | 1 | 対照群 | 3 | 146.824 |
| 4 | 1 | 対照群 | 4 | 140.422 |
| 5 | 1 | 対照群 | 5 | 133.076 |
| 6 | 2 | 介入群 | 1 | 130.799 |
| 7 | 2 | 介入群 | 2 | 169.138 |
| 8 | 2 | 介入群 | 3 | 158.752 |
| 9 | 2 | 介入群 | 4 | 131.655 |
| 10 | 2 | 介入群 | 5 | 138.241 |
上記のプログラムでは乱数生成の際にシードを設定しています。これは乱数生成を開始する初期値を与えているのです。同じシードを設定すれば毎回同じデータを生成できます。
ここからSGPLOTプロシジャでグラフを作成します。まず2群の平均値の推移をグラフで表現します。
proc sgplot data=d1; vline visit / /*vlineステートメント:折れ線グラフの表示(X軸の変数指定)*/ response=bp /*responseオプション:y軸の変数の指定*/ group=group /*groupオプション:グループ変数の指定*/ stat=mean /*statオプション:プロットする統計量(平均値)*/ markers /*markersオプション:プロットに◯を表示*/ limitstat=stddev; /*limitstatオプション:SD, SE, CIのどれかを表示*/ format group groupf.; /*formatプロシジャで設定したラベルの指定*/ run;
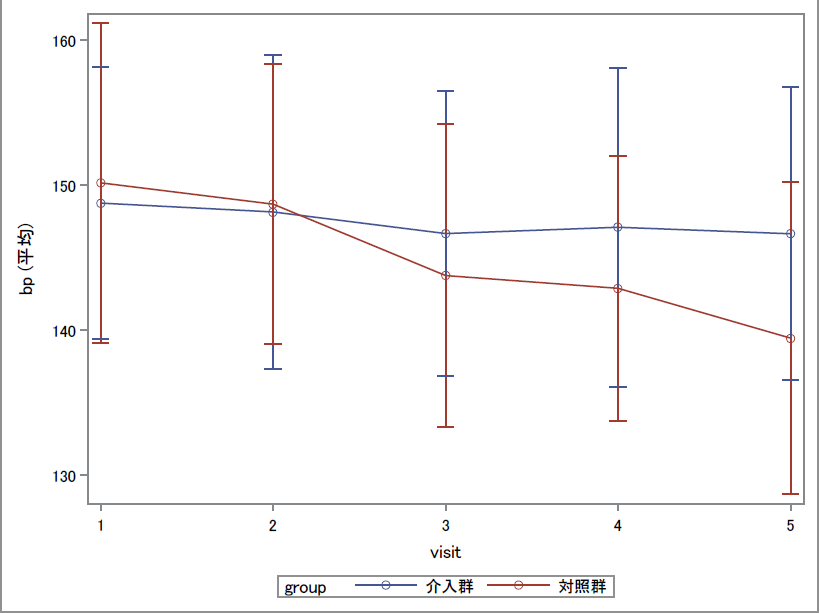
統計量の推移をグラフ化するのに使用するのがVLINEステートメントです。これは折れ線グラフの図示に使用されるもので、経時測定データの平均値推移のグラフでよく使用されます。
これだと標準偏差のバーが2群間で重なっていて見づらいかもしれません。その場合はgroupdisplayオプションで分けることができます。またグラフ内に各時点での平均値を表示したい場合は、Xaxistableステートメントで表示可能です。
proc sgplot data=d1; vline visit / response=bp group=group stat=mean limitstat=stddev groupdisplay=cluster /*groupdisplayオプション:2群のプロットをずらして表示*/ markers; xaxistable bp/ /*Xaxistableステートメント:表示する変数の指定*/ separator /*グラフと平均値表を線で分ける*/ stat=mean /*表示する統計量の指定*/ loaction=inside; /*locationオプション:表示位置の指定(inside, outside)*/ format group groupf.; run;
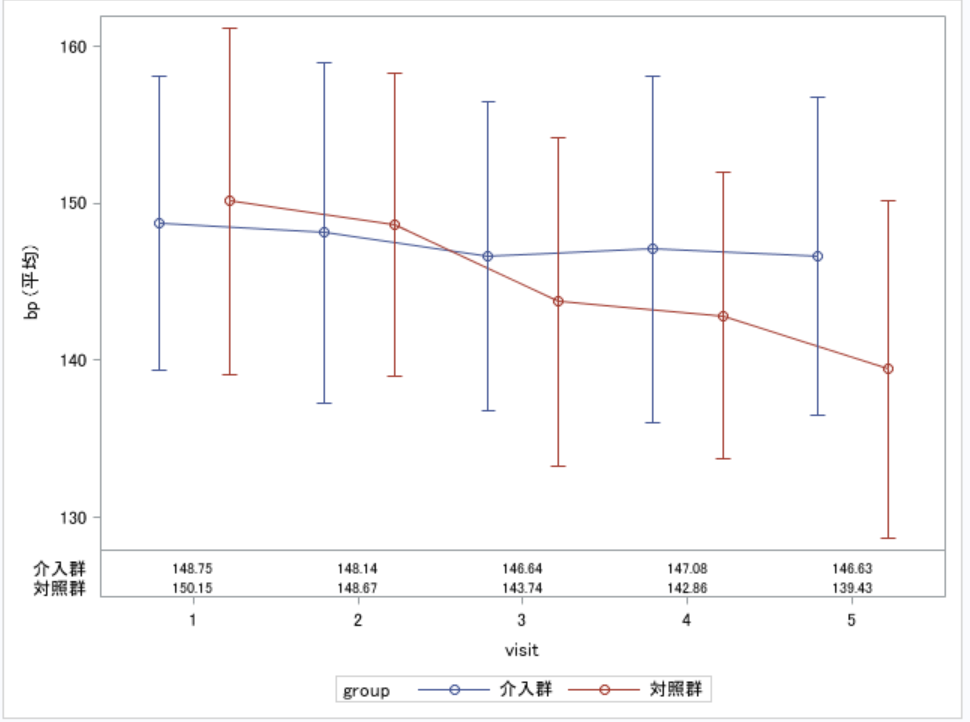
以上のプログラムは一部のオプションしか紹介できていませんが、VLINEステートメントだけでも非常に多くのオプションがあります。まずはよく使うものだけ覚えて、適宜ヘルプで調べるのが良いでしょう。
場合によっては平均値ではなく、個人ごとの推移をみたい場合もあるかもしれません。
その場合は時系列プロットが可能なseriesステートメントの出番です。
proc sgplot data=d1; series x=visit y=bp/ group=group ; format group groupf.; run;
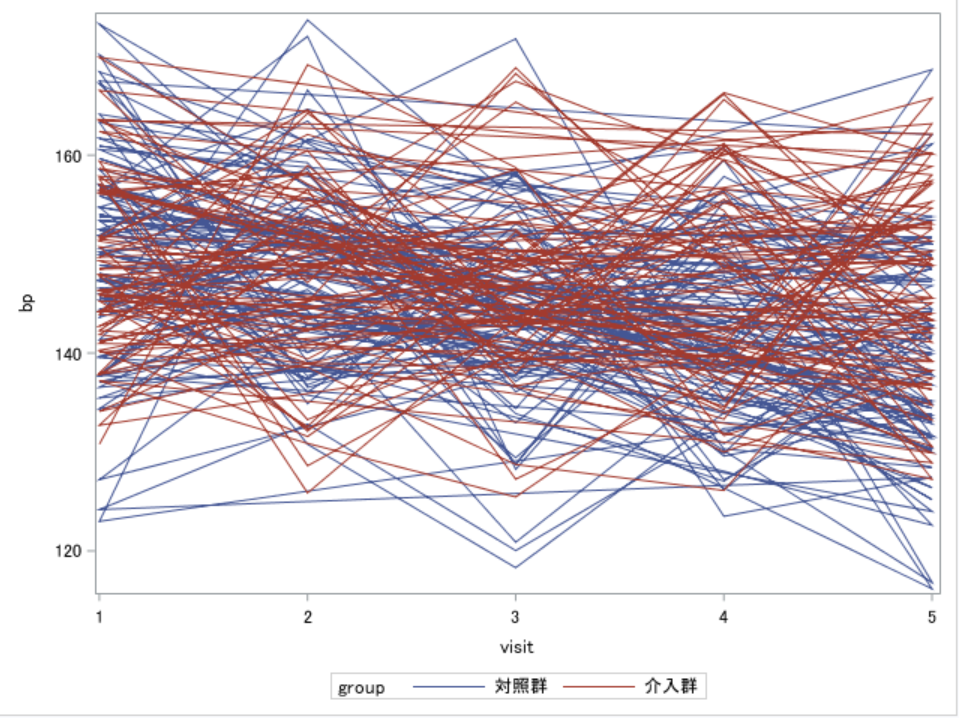
今回のデータでは非常に見づらくなっていますが、研究によっては個人ごとの推移が見たい場合もあります。
●困ったときのSASヘルプ
https://documentation.sas.com/?docsetId=grstatproc&docsetTarget=n0yjdd910dh59zn1toodgupaj4v9.htm&docsetVersion=9.4&locale=en
●SASのSGPLOTとRのGGPLOT2を比較する面白い資料
https://www.sas.com/content/dam/SAS/ja_jp/doc/event/sas-user-groups/usergroups2016-b-02-06.pdf
Transpose プロシジャ
経時測定データの解析やグラフ作成において欠かせないのが、列と行の転置です。
行と列の転置をする際に使用するのが、Transposeプロシジャです。
以下のような各対象者の4時点のアウトカムが測定された、経時測定データを想定します。
data d1;
do ID=1 to 100;
time1=rand("normal", 130, 10) - 1;
time2=rand("normal", 130, 10) - 2;
time3=rand("normal", 130, 10) - 3;
time4=rand("normal", 130, 10) - 4;
output;
end;
run;| Obs | ID | time1 | time2 | time3 | time4 |
|---|---|---|---|---|---|
| 1 | 1 | 120.212 | 120.113 | 136.648 | 147.289 |
| 2 | 2 | 121.143 | 116.871 | 118.837 | 130.571 |
| 3 | 3 | 133.928 | 145.323 | 128.351 | 103.948 |
| 4 | 4 | 137.547 | 116.522 | 135.479 | 118.871 |
| 5 | 5 | 130.469 | 130.480 | 121.440 | 122.957 |
| 6 | 6 | 128.345 | 139.289 | 134.042 | 142.513 |
| 7 | 7 | 146.649 | 132.147 | 130.313 | 151.464 |
| 8 | 8 | 108.033 | 145.543 | 127.546 | 107.512 |
| 9 | 9 | 146.863 | 138.182 | 117.447 | 134.335 |
| 10 | 10 | 122.465 | 138.447 | 120.752 | 129.347 |
上記のデータから、4時点のアウトカムデータを以下のように一列で表示することを考えます。
| Obs | ID | time | x1 |
|---|---|---|---|
| 1 | 1 | time1 | 120.212 |
| 2 | 1 | time2 | 120.113 |
| 3 | 1 | time3 | 136.648 |
| 4 | 1 | time4 | 147.289 |
| 5 | 2 | time1 | 121.143 |
| 6 | 2 | time2 | 116.871 |
| 7 | 2 | time3 | 118.837 |
| 8 | 2 | time4 | 130.571 |
ここでTransposeプロシジャを使います。
proc transpose data=d1 out=out prefix=x name=time; var time1 time2 time3 time4; by ID; run;
上記のコードによってtime1~4をX1という一つの変数にまとめることができます。time1~4という時点に関する情報を保持するため、timeという変数を新たに作成しています。
VARステートメントでは転置する変数を指定します。今回のデータではtime1~4を1列にまとめることが目的なので指定しています。
BYステートメントでは各行に対応させる変数を指定します。実際のデータでは被験者IDなどを設定することが多いでしょう。
PROC TRANSPOSEステートメントでは変数名などのオプションを設定することができます。prefixは新しく生成する変数名を指定します。上記のコードでは、time1~4の変数を一つにまとめた際の変数名をXと指定していることになります。nameでは転置元の変数を値として格納する変数の名前を指定しています。上記のコードではtime1~4という値を格納するtimeという変数名を指定しています。
実は今回行った転置の逆を行うことも可能です。
proc transpose data=out out=out1; var x1; by ID; id time; run;
IDステートメントで転置変数のラベルとなる変数を指定します。X1を4つの列に転置する際のラベルを、time変数の値time1~4となるように指定しています。
1変量のデータ要約(Univariateプロシジャ)
SASによる1変量の記述統計の出力方法です。
まずは正規乱数でデータを生成します。以下のような2群データを想定しています。
data bp;
do No=1 to 200;
if No<=100 then group="treat";
if No>100 then group="placebo";
if No<=100 then bp=rand("normal", 130, 10);
if No>100 then bp=rand("normal", 140, 10);
output;
end;
run;
| No | group | bp |
|---|---|---|
| 1 | treat | 120.795 |
| 2 | treat | 121.15 |
| 3 | treat | 127.129 |
| 4 | treat | 140.005 |
| 5 | treat | 133.352 |
| 6 | treat | 135.889 |
| 7 | treat | 113.716 |
| 8 | treat | 126.45 |
| 9 | treat | 132.932 |
| 10 | treat | 118.033 |
今回はtreat群とplacebo群でそれぞれ記述統計を出力します。
1変量の記述統計を表示するには、Univariateプロシジャを使用します。
proc sort data=bp; by group; run; proc univariate data=bp normal plot; id No; var bp; by group; output out=out1 n=N mean=Mean std=STD median=Median qrange=Qrange; run;
まずPROC Univariate ステートメントで解析に使用するデータ(data=)を指定します。追加のオプションとして、正規性プロット(normal)やグラフ(plot)を出力するかどうかを指定できます。
idステートメントでは対象者番号を参照し、varステートメントで要約する変数を指定します。
byステートメントでカテゴリー変数を指定することで、記述統計を群ごとに出力できます。注意点は、byステートメントで指定する場合、データが事前に昇順に並び替えられていることが必要です。今回の場合、placebo群、treat群の順にアルファベット順にソートする必要があります。そのためSORTプロシジャで事前にデータをgroup変数でソートしておきます。
またOutputステートメントでは、データセットに要約統計量を出力することができます。対象者数(n=対象者ラベル)、平均(mean=平均ラベル)、のように自由に変数にラベルを指定することができます。


ヒストグラムや箱ひげ図に加えて、正規分布に従っているかどうかを確認するためのQ-Qプロットも出力してくれます。
Univariateプロシジャは一度に多くの記述統計量を表示できるため便利ではありますが、平均や分散だけ表示したい場合もあります。
その場合は、MeansプロシジャやSummaryプロシジャを使ったほうが良いでしょう。